Between late December 2025 and mid-February 2026, a single threat actor used Claude Code and OpenAI’s GPT-4.1 to breach nine Mexican government agencies. Claude Code generated and executed about 75% of the remote commands across the intrusion. The attacker exfiltrated 150 gigabytes of taxpayer, civil registry, electoral, and health data, including 195 million taxpayer records.1
The breach matters because of leverage. One operator used an agent to compress reconnaissance, command generation, error recovery, and iteration into a continuous loop. If autonomous tooling makes intrusion that cheap to run, defenders need ways to slow it down and raise its cost.
Autonomous attackers do more than run tools faster. They build a working model of the environment from what they read along the way: command output, error messages, filenames, banners, and credentials. That model is useful to them, but it’s also fragile in certain ways.
Adaptive deception attacks that dependency. The defender poisons what the agent observes, plants tripwires in likely recon paths, and changes selected parts of the environment so reconnaissance goes stale before it can be used. The goal is cost imposition: more false paths, more retries, more tool calls, and earlier detection.
The research project I am building tests one question. Can adaptive deception make an autonomous attacker slower, noisier, and easier to detect?
Why deception changes with autonomous agents
None of this starts from scratch. Deception has always been about giving the attacker bad information while they are trying to build a plan. The old definition still holds: intentionally falsified information meant to sabotage reconnaissance and planning.2 Newer reviews expand the taxonomy and compare AI-enabled deception systems with non-AI systems.3 The useful question now is what changes when the attacker is an autonomous agent.
What changes is that the attacker now reads more of the environment and keeps state while doing it. Agentic AI systems reason and adapt over long tasks using memory, tool calls, and iterative decision cycles. Recent survey work on agentic AI and cybersecurity makes the dual-use case explicit: those same traits can accelerate reconnaissance, exploitation, coordination, and social engineering.4
That dependence on observation creates a different defensive surface. An autonomous attacker has to observe, interpret, plan, act, and update. To do that, it parses error messages, scrapes documentation, stores partial findings, follows credential-looking strings, retries failed commands, and spends tokens every time it reads or plans.
Microsoft’s guidance on OpenClaw frames the runtime risk: self-hosted agent runtimes can ingest untrusted text, run third-party skills, operate with assigned credentials, and maintain state or memory that can be modified over time. Microsoft also calls out indirect prompt injection, where instructions hidden inside content read by the agent can steer tool use or trigger disclosure.5
The core idea
Treat honeypots, canaries, decoy services, and moving-target defense as one operating model that corrupts what the attacker reads as the environment.
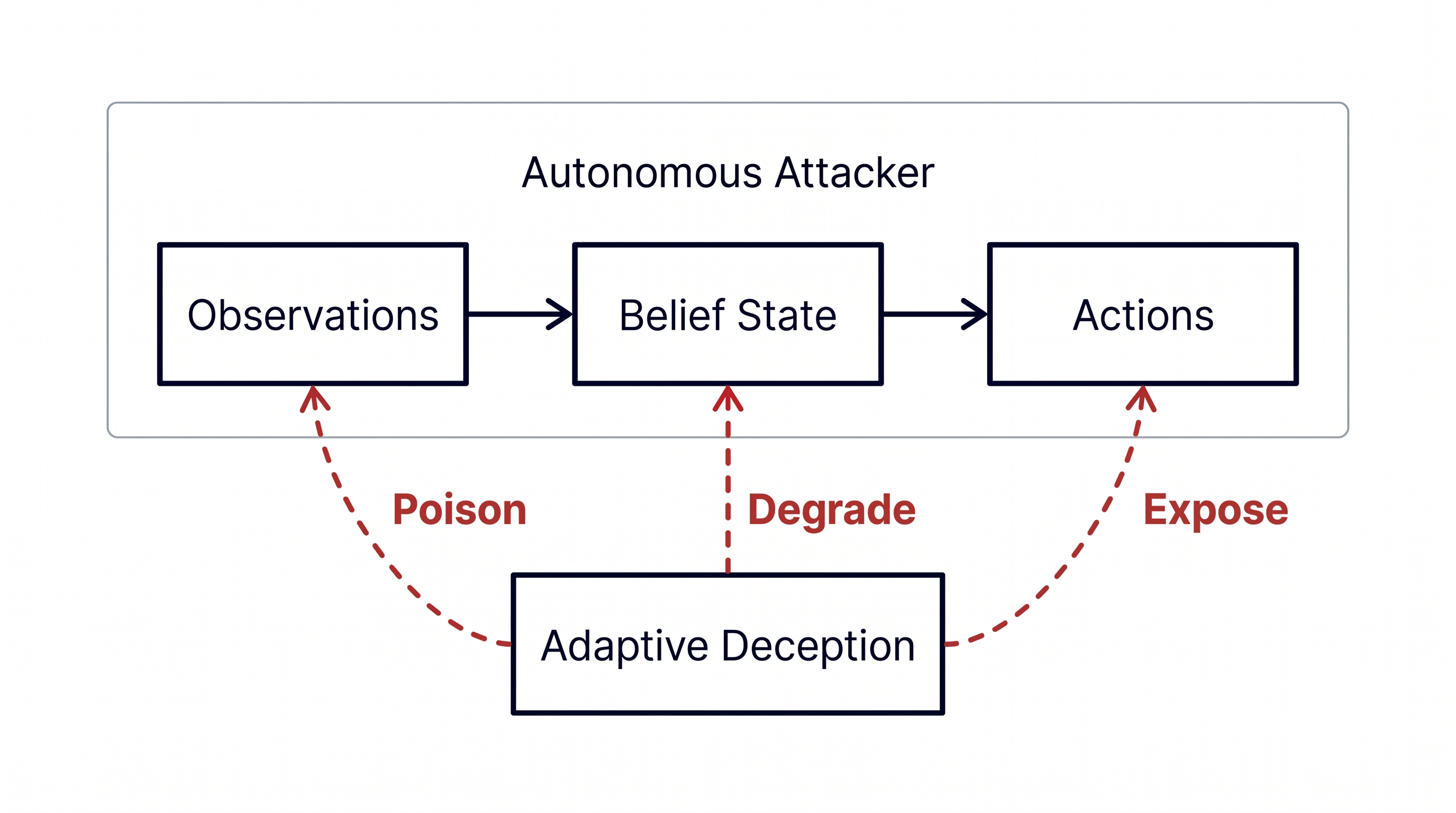
Figure 1 - The attacker’s observe-believe-act loop, and where adaptive deception corrupts it.
Adaptive deception is selective. Decoys go in paths an attacker is likely to inspect, stay out of high-traffic user workflows, and change only when attacker behavior justifies it. A disciplined deployment gives defenders a cleaner signal than another low-confidence anomaly.
The operating model has four parts:
| Mechanism | Attacker effect | Defender benefit |
|---|---|---|
| Poisoned recon | Builds plans on falsified observations | Earlier detection at the recon stage |
| Tripwires | Touching a decoy reveals the line of inquiry | High-confidence alert tied to specific intent |
| Non-metronomic churn | Reconnaissance goes stale before action | Stale plans force replanning and retries |
| Cost imposition | Burns tokens, tool calls, and wall-clock time | Raises the marginal cost of each campaign |
The adaptive deception model
Poison what the agent reads. Traditional deception poisoned reconnaissance with honeypots and decoy services. The difference now is that the decoy has to survive contact with tooling that can read, summarize, compare, retry, and explain.
LLM-driven honeypots show what that can look like. LLMHoney uses a virtual filesystem plus LLM-generated responses to simulate SSH interactions in real time. In its evaluation across 138 Linux commands, smaller models produced useful responses with mean latencies around three seconds.6
HoneyAgents is another proof of concept in the same direction: honeypots coupled with autonomous AI agents for threat analysis and response.7
Most decoys do not need an LLM behind them, and most should not. But static fakery is easier to fingerprint when the attacker can reason over inconsistencies. A credential-looking file has to look plausible in the context where the agent finds it, a service banner has to fit the host, and a document lure has to match the path that led the attacker there.
The agent is building a belief state. Deception works when it corrupts that state without revealing itself.
Detect what the agent touches. Canary tokens are useful because they turn curiosity into signal. A token in an inbox, cloud folder, internal wiki page, fake key file, or high-value document tells the defender which line of inquiry the attacker followed.
Against a normal scanner, text hidden in a document or comment may be invisible. Against an autonomous agent that reads and follows semantic leads, that same text becomes a tripwire. A credential-looking string in a shared drive separates broad scanning from intent.
A tripwire that no legitimate user should touch is more useful than another heuristic that needs ten minutes of analyst interpretation.
Rotate what the agent thinks it knows. Moving-target defense belongs in the same operating model, but predictable movement is not enough.
The MTDSense paper shows the limit of predictable moving-target defenses. The authors demonstrate that an attacker can use unsupervised clustering on traffic to infer when an IP-shuffling defense has been triggered and extract the rotation interval.8
That matters for autonomous attackers. An agent that can learn a fixed rotation interval can plan around it: wait out a cycle, repeat discovery, and preserve the part of the map that still looks reliable while rebuilding the rest.
Adaptive deception needs structural churn that is harder to model from the outside. The better direction is observation-triggered change and controlled randomness: rotated service banners, fresh lure files dropped during enumeration, identity or placement shifts that invalidate stale recon, and decoy material that changes when the agent commits to a path.
The ADA authors push this idea at the infrastructure layer by rotating AI workloads in Kubernetes through continuous destruction and respawn of service instances.9 The Kubernetes specifics will not fit every environment, but the principle does: the agent’s map of the environment should decay faster than the agent can use it.
Burn the reasoning budget. LLM-based agents pay for reasoning in tool calls and token-billed inference. Every directory listing, error message, log snippet, failed command, planning step, and retry has a cost, which makes cost a defensive dimension.
The Clawdrain paper, from the offensive side, shows how agent frameworks can be pushed into costly token-exhaustion loops through tool-calling chains.10 I do not want a defense strategy that depends on brittle prompt tricks, but the underlying observation is useful: agents can be made to spend compute on the wrong thing.
In an intrusion, the cost does not need to bankrupt the attacker. It only has to change the economics. More time in the environment gives defenders more chances to detect. Forced replanning surfaces mistakes. Wasted tool calls eat into the campaign’s budget.
My claim is modest. Adaptive deception is worth the engineering effort if it produces measurable changes in attacker behavior.
The research question
Does selective, adaptive deception change how an autonomous attacker behaves in a controlled environment?
The measurable sub-questions:
- Does deception increase the time it takes an agent to identify a valid path?
- Does it cause the agent to touch more false assets or chase more dead ends?
- Does it increase retries, replanning, token use, or tool consumption?
- Does it create earlier or higher-confidence detection opportunities for the defender?
If the answers are yes, adaptive deception is a measurable cost-imposition strategy.
Whether deception “stopped the intrusion” is the wrong first measure. A binary blocked-or-not view hides the effect I care about.
The better measures are behavioral:
- Median Time-to-Objective. Wall-clock time from agent start to objective completion across runs.
- Time to First Real Asset. How long the agent takes to identify the first non-decoy target.
- False-Path Ratio. Decoy interactions divided by total interactions. This should rise if the environment corrupts the agent’s belief state.
- Context Growth. How much the agent’s session memory bloats from absorbing fabricated data, which raises the cost of later reasoning cycles.
- Tool and Token Burn. The number of commands, tool calls, prompts, and tokens spent before success, failure, or timeout.
- Detection Lead Time. How early a defender gets a high-confidence signal compared with objective completion.
Shahin et al. also introduce two useful metrics in their 2026 paper Evaluating Synthetic Cyber Deception Strategies Under Uncertainty via Game Theory Approach. The value of deception measures the improvement in defender utility attributable to deception:
$$V_{oD} = \frac{U_\text{Deception} - U_\text{Baseline}}{U_\text{Baseline}}$$
The price of transparency captures utility loss when the deception strategy becomes observable to the attacker:
$$P_{oT} = \left| U_\text{Deception} - U_\text{Transparent} \right|$$
That framing is useful because it forces the defender to ask whether a decoy changed attacker utility, not just whether it looked clever.11
The initial harness
The initial plan is narrow and reproducibility-first. I am building a benchmark harness around a GOAD Active Directory lab, with Claude Code operating from a Kali attacker VM against a fixed snapshot, fixed prompt, and fixed starting account. Each run captures transcripts, timing, termination reason, and run provenance so later comparisons are defensible.
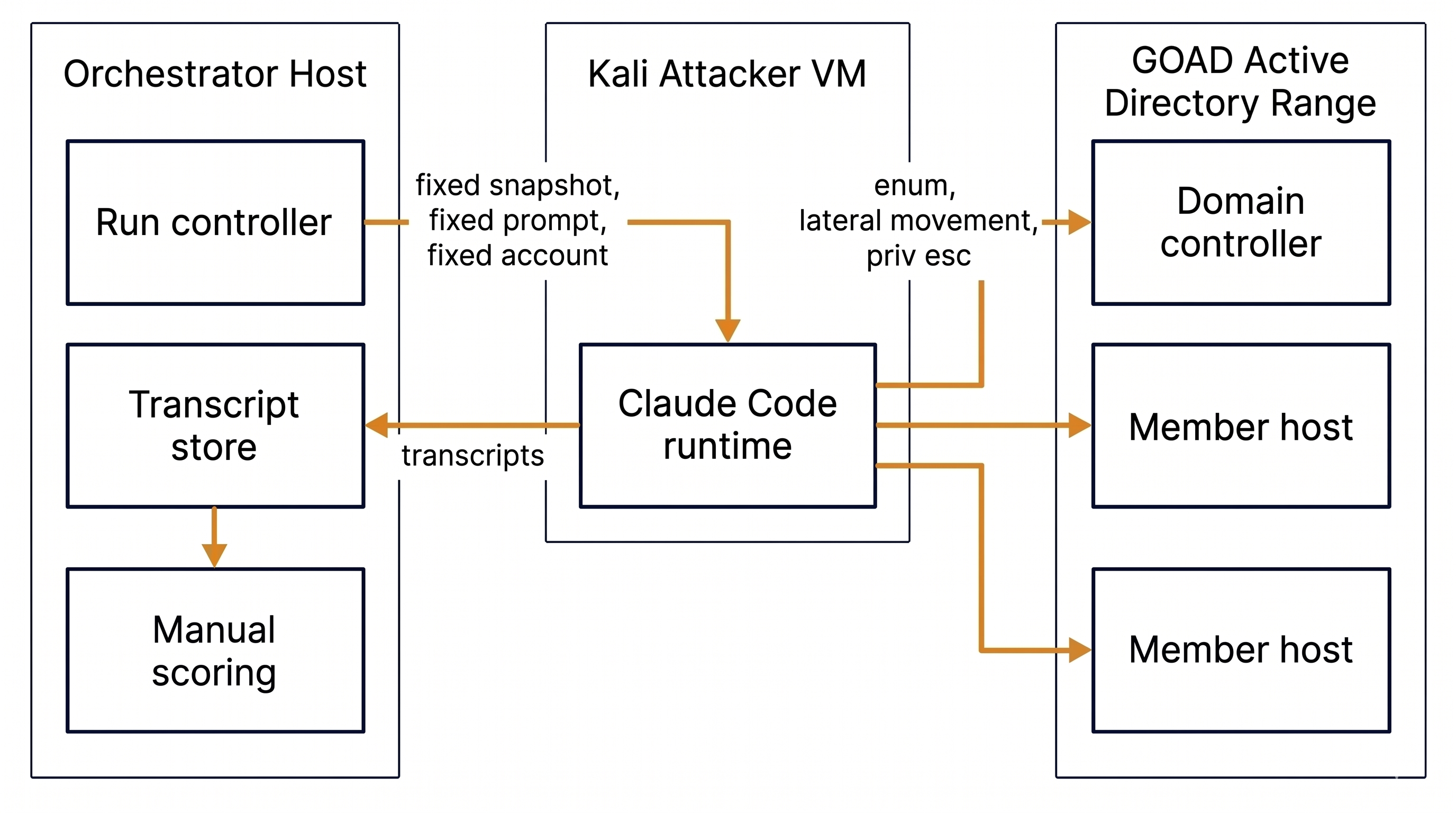
Figure 3 - Benchmark harness: orchestrator drives Claude Code against a fixed GOAD snapshot.
The harness compares the same agent across three environments:
- Clean baseline. A poorly segmented AD network with no decoys, no mutation, and no canaries. This establishes how quickly Claude Code completes the objective when facing only traditional perimeter friction.
- Static deception. The same network with a small number of high-fidelity decoy hosts, decoy services, and document lures placed in likely recon paths. Decoys never change between or within runs. This tests whether the agent can fingerprint static traps through semantic reasoning or latency analysis.
- Adaptive deception. Static deception plus environment mutation triggered by attacker behavior: rotated service banners, fresh lure files dropped during enumeration, and non-metronomic infrastructure changes that make stale recon unreliable.
The agent’s objective is identical in each environment: reach Enterprise Admin-equivalent control in the AD lab and produce proof on the forest root.
I want repeated attacker runs from the same starting state in each environment, followed by conservative manual review of each transcript. The scoring ladder is small: meaningful enumeration, lateral movement, privilege escalation, and domain-admin-equivalent access.
I also want the harness to track the cost side of the interaction, not just the end state. That means token use, context size, tool calls, decoy interactions, wall-clock time, and replanning events.
Limits and boundaries
Static deception gets fingerprinted. Blanket deception floods analysts with noise. Sloppy lures trip normal users. A fake payroll share that real employees keep opening is not a tripwire; it is self-inflicted alert fatigue. Deception outside infrastructure you control creates legal and operational risk.
The useful version of this strategy is selective and internal. Decoys should appear where the signal justifies them. Tripwires should sit where legitimate users rarely go. Environment shifts should hurt attacker planning more than normal operations.
There is also a measurement risk. If I change too many things at once, I will not know what mattered. That is why the first experiment starts with a clean baseline and introduces deception conditions one at a time.
Where this goes next
AI attackers depend on observations, remembered state, external tools, and inference budgets. A defender that poisons those dependencies raises the cost of autonomous offense.
The next post establishes the clean baseline. After that, deception conditions go in one at a time, and I publish what changes.
SOCRadar, Claude Code & ChatGPT Used to Steal Millions of Records in Mexican Government Breach (2026). ↩︎
Zhuo Lu, Cliff Wang, and Shangqing Zhao, Cyber Deception for Computer and Network Security: Survey and Challenges (arXiv, 2020). ↩︎
Pedro Beltran Lopez, Manuel Gil Perez, and Pantaleone Nespoli, Cyber Deception: State of the art, Trends and Open challenges (arXiv, 2024). ↩︎
Sahaya Jestus Lazer, Kshitiz Aryal, Maanak Gupta, and Elisa Bertino, A Survey of Agentic AI and Cybersecurity: Challenges, Opportunities and Use-case Prototypes (arXiv, 2026). ↩︎
Microsoft Security Blog, Running OpenClaw safely: identity, isolation, and runtime risk (February 19, 2026). ↩︎
Pranjay Malhotra, LLMHoney: A Real-Time SSH Honeypot with Large Language Model-Driven Dynamic Response Generation (arXiv, 2025). ↩︎
mrwadams, HoneyAgents (GitHub). ↩︎
Tina Moghaddam et al., MTDSense: AI-Based Fingerprinting of Moving Target Defense Techniques in Software-Defined Networking (arXiv, 2024). ↩︎
Akram Sheriff et al., ADA: Automated Moving Target Defense for AI Workloads via Ephemeral Infrastructure-Native Rotation in Kubernetes (arXiv, 2025). ↩︎
Ben Dong, Hui Feng, and Qian Wang, Clawdrain: Exploiting Tool-Calling Chains for Stealthy Token Exhaustion in OpenClaw Agents (arXiv, 2026). ↩︎
Mohammad Shahin, Mazdak Maghanaki, and Fengshan Frank Chen, Evaluating Synthetic Cyber Deception Strategies Under Uncertainty via Game Theory Approach: Linking Information Leakage and Game Outcomes in Cyber Deception (Sensors, 2026). ↩︎